
东坡肉、蘑菇炒青菜、清蒸鲫鱼、虾仁豆腐……做了满满一桌菜,拍张照片扔给AI,问它:图片里的哪种食物蛋白质含量最高?哪道菜尿酸偏高的人不宜多吃?
AI深度思考了几秒钟,打出推理全过程,最后在图片上将答案圈了出来。
这是学会推理的多模态大模型,未来在日常生活中的一个应用小场景。此前,这种“长眼睛”、擅长推理的AI还停留在想象阶(jiē)段。不过最近,来自杭州Om AI Lab的一群95后,已经成功地将DeepSeek-R1的训练方法,从纯文本领域迁移到视觉语言领域,打开了多模态大模型的更多想象空间。
他们还将这个名叫VLM-R1的项目开源,发布在全球最大的代码托管平台GitHub上,上线仅一周,就获得各国开发者给出的(de)2.7k Stars(星(xīng)标(biāo)),并(bìng)在(zài)2月(yuè)21日(rì)登(dēng)上(shàng)热(rè)门(mén)趋(qū)势(shì)榜(bǎng)。这(zhè)一(yī)成(chéng)绩(jī)在(zài)这(zhè)个(gè)开(kāi)源(yuán)社(shè)区(qū)里(lǐ)堪(kān)称(chēng)亮(liàng)眼(yǎn)。
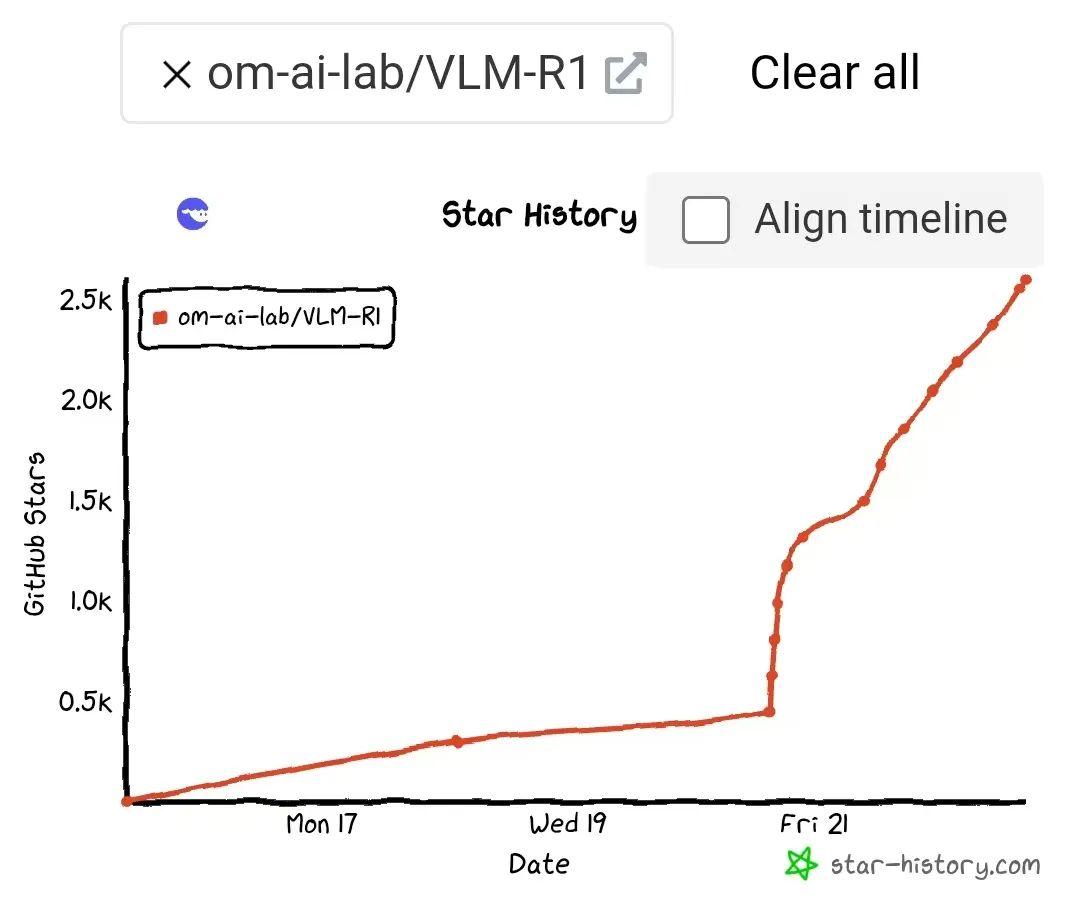 VLM-R1上(shàng)线(xiàn)GitHub一(yī)周(zhōu)的(de)Star(星(xīng)标(biāo))数(shù)据(jù)曲(qū)线(xiàn)
VLM-R1上(shàng)线(xiàn)GitHub一(yī)周(zhōu)的(de)Star(星(xīng)标(biāo))数(shù)据(jù)曲(qū)线(xiàn)

2月21日上了GitHub热门趋势榜
这支研发团队的带头人,是名90后——Om AI Lab的创始人赵天成博士,他同时也是浙江大学滨江研究院Om人工智能中心主任、博士生导师。
将教DeepSeek-R1推理的方法
带到机器视觉领域
DeepSeek-R1模型的独特之处,在于DeepSeek对(duì)通(tōng)用(yòng)的(de)模(mó)型(xíng)推理步骤(zhòu)进(jìn)行(xíng)了(le)调整。此前,模型在提升推理能力时,通常依赖“监督微调”(即SFT,监督式微调)这个环节。简单来说,就是拿一个已经学了不少东西的大模型,用一些特定的、标记好的数据,来教它如何更好地完成某个任务。这就好比你已会做菜,但具体到川菜或徽菜,还需通过专门的练习来掌握烹饪技巧。
而DeepSeek-R1在训练过程中直接跳过了这个环节,进入“强化学习”阶段,探索大模型在没有监督数据的情况下,通过纯强化学习进行自我进化。这种创新性的强化学习方法,有个专业名词,叫群组相对策略优化(Group Relative Policy Optimization,GRPO)。
GRPO已经帮助DeepSeek-R1学习推理,那是否也能帮助AI模型在一般计算机视觉任务中表现得更强?
Om AI Lab研发团队反复实验后的答案是:可以。
他们在一个视觉定位任务中,训练了通义开源视觉理解模型Qwen2.5-VL。在此基础上,同时用R1方法和SFT方法进行对比。目前得出的结论是:R1方法在各种复杂场景下,都能保持稳定的高性能。这在实际应用时至(zhì)关重(zhòng)要(yào)。
如(rú)下图的街景照片,给AI的任务是:定位出图中可能对视障人士行走造成危险的物体。

在路边人行道的场景里,人类能想到对视障人士造成行走障碍的,通常是石墩子、公交站牌、行人等,这些就是可以提前标记好的“数据”。但在这张图中,出现了一个比较特殊的情况——台阶。
从赵天成团队的实验看,经过R1方法训练的AI模型,能够成功推理出台阶在这个场景中会对视障人士造成危险。
“对人类来说,这属于常识性推理,再容易不过。但对于此前传统的计算机视觉模型而言,这其实非常难。”赵天成解释。
又如下面这张图,桌子上放着山药、鸡蛋饼、毛豆、青菜、咖啡和橙子,让AI定位图中含维生素C最多的食物。

使用R1方法训练的AI模型,很快锁定了橙子并附上思考过程。“以前它直给答案,不会告诉你解题思路,且错误率偏高,比如10道题最多答对四五题,而用R1方法训练的,能答对七八题。”
此外,机器学习领域有一种很常见的情况:用任务A去训练模型,随着训练步数(训练模型所执行的迭代次数)的增加,在跟A没有那么相似的任务B上,它的性能会变差(图中红色曲线)。“有点‘摁了葫芦起了瓢’的意思。所以以前做多任务时,还要精心控制任务间的比例。”而使用R1方法训练的AI模型(图中绿色曲线)并不会出现这种趋势,这意味着R1方法能帮助模型真正“学会”理解视觉内容,而不是简单地记忆。
 绿色曲线是使用R1方法训练,红色曲线是使用(yòng)传(chuán)统(tǒng)的(de)SFT方(fāng)法(fǎ)。
绿色曲线是使用R1方法训练,红色曲线是使用(yòng)传(chuán)统(tǒng)的(de)SFT方(fāng)法(fǎ)。
为(wèi)视(shì)觉(jué)语(yǔ)言(yán)模(mó)型(xíng)训(xun)练(liàn)
打(dǎ)了(le)新(xīn)思(sī)路
“实(shí)验(yàn)从(cóng)春(chūn)节(jié)长(zhǎng)假(jiǎ)期(qī)间(jiān)开(kāi)始(shǐ)启(qǐ)动(dòng)。好(hǎo)在(zài)前(qián)期(qī)积(jī)累(lèi)比(bǐ)较(jiào)多(duō),很(hěn)多(duō)‘基(jī)础(chǔ)设(shè)施(shī)’是(shì)现(xiàn)成(chéng)的(de),有(yǒu)了(le)想(xiǎng)法(fǎ)后(hòu),能(néng)快(kuài)速(sù)进(jìn)行(xíng)实(shí)验(yàn)、验(yàn)证(zhèng)结(jié)果(guǒ)。”组(zǔ)成(chéng)团(tuán)队(duì)的(de)10人(rén),有(yǒu)研(yán)究(jiū)院(yuàn)的(de)研(yán)发人员,也有赵天成带的博士生。
2月15日,赵天成在海外社交平台上发布VLM-R1的实验结果,并将它开源、上传到GitHub,截至2月22日,已获得全球开发者们给出的(de)2.7k Stars。

大大小小的(de)交(jiāo)流(liú)切(qiè)磋(cuō)问题蜂拥而来:要训练多久,最低显存是多少,能否再多分享几个模型思考过程……
“虽然底层逻辑是相通的,但视觉和数学、代码是完全不同的模态。怎么在视觉领域进行设计,让它真正跑通,团队其实也经历了多次试错,才找到目前这样一个比较有效的组合。”赵天成坦言,现在这个版本只能算是0.1版,远未达到成熟,“有一些问题,需要继续用更多实验(yàn)来(lái)解(jiě)答(dá)。”
在(zài)他(tā)看(kàn)来(lái),这(zhè)段(duàn)时(shí)间(jiān)的(de)实(shí)验(yàn),最(zuì)大(dà)意义之一是为多模态模型的训练和行业提供了一些新的思路。它证明了R1方法的通用性,“不仅在文本领域表现出色,还可能引领一种全新的视觉语言模型训练潮流。”
“做(zuò)一(yī)个(gè)勇(yǒng)于(yú)尝(cháng)试(shì)的(de)引(yǐn)领(lǐng)者(zhě)
比(bǐ)在(zài)风(fēng)口(kǒu)追(zhuī)随(suí)着(zhe)他(tā)人(rén)来(lái)得(de)重(zhòng)要(yào)”
Om AI Lab背(bèi)后(hòu)的(de)母(mǔ)公(gōng)司(sī)联(lián)汇(huì)科(kē)技(jì),位(wèi)于(yú)杭(háng)州(zhōu)滨(bīn)江(jiāng)互(hù)联(lián)网(wǎng)产(chǎn)业(yè)园(yuán),这(zhè)里(lǐ)曾(céng)是(shì)阿(ā)里(lǐ)、网(wǎng)易(yì)崛起的摇篮,互联网和物联网技术从这里走入我们的日常生活。眼下,人工智能成了主角,这家公司正在致力于人工智能智能体平台的应用和落地。
2月21日,由赵天成带队的Om AI Lab,在上海举行的2025全球开发者先锋大会(GDC)上,带去了基于R1强化学习的视觉理解多模态模型VLM-R1的首秀,以及开源大语言模型智能体评测平台Open Agent Leaderboard。

赵天成 (陈中秋 摄)
去年8月,赵天成在接受采访时说,他始终记得当年在美国卡耐基梅隆大学(CMU)求学时导师说的一句话:To be a leader, not a follower,做一个勇于尝试的引领者,远比在风口追随着他人来得重要。
(来源:潮新闻)
